
Spring AOP切面解决数据库读写分离实例详解
为了减轻数据库的压力,一般会使用数据库主从(master/slave)的方式,但是这种方式会给应用程序带来一定的麻烦,比如说,应用程序如何做到把数据写到master库,而读取数据的时候,从slave库读取。如果应用程序判断失误,把数据写入到slave库,会给系统造成致命的打击。
解决读写分离的方案很多,常用的有SQL解析、动态设置数据源。SQL解析主要是通过分析sql语句是insert/select/update/delete中的哪一种,从而对应选择主从。而动态设置数据源,则是通过拦截方法名称的方式来决定主从的,例如:save*(),insert*() 形式的方法使用master库,select()开头的,使用slave库。蛮多公司会使用在方法上标上自定义的@Master、@Slave之类的标签来选择主从,也有公司直接就调用setxxMaster,setxxSlave之类的代码进行主从选择。
下面我主要介绍一下基于Spring AOP动态设置数据源这种方式。注意这篇文章是基于自己项目的实际情况的,不是通用的方案,请知晓。
原理图
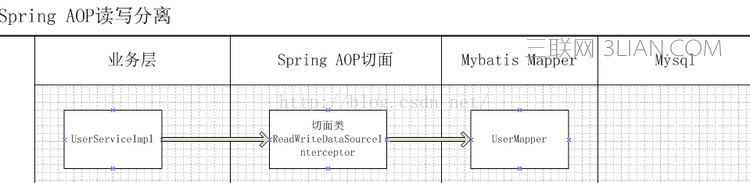
Spring AOP的切面主要的职责是拦截Mybatis的Mapper接口,通过判断Mapper接口中的方法名称来决定主从。
Spring AOP 切面配置
<aop:config expose-proxy="true">
<aop:pointcut id="txPointcut" expression="execution(* com.test..persistence..*.*(..))" />
<aop:aspect ref="readWriteInterceptor" order="1">
<aop:around pointcut-ref="txPointcut" method="readOrWriteDB"/>
</aop:aspect>
</aop:config>
<bean id="readWriteInterceptor" class="com.test.ReadWriteInterceptor">
<property name="readMethodList">
<list>
<value>query*</value>
<value>use*</value>
<value>get*</value>
<value>count*</value>
<value>find*</value>
<value>list*</value>
<value>search*</value>
</list>
</property>
<property name="writeMethodList">
<list>
<value>save*</value>
<value>add*</value>
<value>create*</value>
<value>insert*</value>
<value>update*</value>
<value>merge*</value>
<value>del*</value>
<value>remove*</value>
<value>put*</value>
<value>write*</value>
</list>
</property>
</bean>
把所有Mybatis接口类都放置在persistence下。配置的切面类是ReadWriteInterceptor。这样当Mapper接口的方法被调用时,会先调用这个切面类的readOrWriteDB方法。在这里需要注意<aop:aspect>中的order="1" 配置,主要是为了解决切面于切面之间的优先级问题,因为整个系统中不太可能只有一个切面类。
Spring AOP 切面类实现
public class ReadWriteInterceptor {
private static final String DB_SERVICE = "dbService";
private List<String> readMethodList = new ArrayList<String>();
private List<String> writeMethodList = new ArrayList<String>();
public Object readOrWriteDB(ProceedingJoinPoint pjp) throws Throwable {
String methodName = pjp.getSignature().getName();
if (isChooseReadDB(methodName)) {
//选择slave数据源
} else if (isChooseWriteDB(methodName)) {
//选择master数据源
} else {
//选择master数据源
}
return pjp.proceed();
}
private boolean isChooseWriteDB(String methodName) {
for (String mappedName : this.writeMethodList) {
if (isMatch(methodName, mappedName)) {
return true;
}
}
return false;
}
private boolean isChooseReadDB(String methodName) {
for (String mappedName : this.readMethodList) {
if (isMatch(methodName, mappedName)) {
return true;
}
}
return false;
}
private boolean isMatch(String methodName, String mappedName) {
return PatternMatchUtils.simpleMatch(mappedName, methodName);
}
public List<String> getReadMethodList() {
return readMethodList;
}
public void setReadMethodList(List<String> readMethodList) {
this.readMethodList = readMethodList;
}
public List<String> getWriteMethodList() {
return writeMethodList;
}
public void setWriteMethodList(List<String> writeMethodList) {
this.writeMethodList = writeMethodList;
}
覆盖DynamicDataSource类中的getConnection方法
ReadWriteInterceptor中的readOrWriteDB方法只是决定选择主还是从,我们还必须覆盖数据源的getConnection方法,以便获取正确的connection。一般来说,是一主多从,即一个master库,多个slave库的,所以还得解决多个slave库之间负载均衡、故障转移以及失败重连接等问题。
1、负载均衡问题,slave不多,系统并发读不高的话,直接使用随机数访问也是可以的。就是根据slave的台数,然后产生随机数,随机的访问slave。
2、故障转移,如果发现connection获取不到了,则把它从slave列表中移除,等其回复后,再加入到slave列表中
3、失败重连,第一次连接失败后,可以多尝试几次,如尝试10次。
处理业务方法中的@Transactional注解
我参与的这个项目,大部分业务代码是不需要事务的,只有极个别情况需要。那么按照上面提到的方案,如果不对业务方法中@Transactional注解进行特殊处理的话,主从的选择会出现问题。大家都知道,如果使用了Spring的事务,那么在同一个业务方法内,只会调用一次数据源的getConnection方法,如果该业务方法内,调用的mapper接口刚好以select开头的,就会选择slave库,那么接下来调用以insert开头的mapper接口方法时,会把数据写入到slave库。如何解决这个问题呢?必须在进入标有@Transactional注解的业务方法前,指定选择master主库。可以通过覆盖DataSourceTransactionManager类中的doBegin方法,如下:
public class MyTransactionManager extendsDataSourceTransactionManager{
@Override
protected void doBegin(Object transaction, TransactionDefinitiondefinition) {
//选择master数据库
super.doBegin(transaction, definition);
}
}
这样既可以避免,把数据写入到从库的问题。
总结
本人的解决方案是基于项目实际的,不一定合适你,我只是展示了解决方案而已。当然你可以选择开源的框架,像阿里的Cobar,360的Atlas。
本文章地址http://www.vzeo.com/news/xuetang/800514.html 由 友站网 编辑整理,转载请注明出处

