
关于这个问题的产生由于我们前端组每个人的编码习惯的差异,最主要的还是因为代码的维护性问题。在此基础上,我对jQuery源码(1.11.3)查找dom节点相关的内容进行了仔细的查阅,虽然并不能理解的很深入 。。同时基于对浏览器console对象的了解产生了一系列之后的问题和分析,对jQuery最常用的三种dom查找方式进行了一个查找效率和性能方面的比较分析。
首先我们要用到的是console.time()和console.timeEnd()这两个成对出现的console对象的方法,该方法的用法是将他们两者之间的代码段执行并输出所消耗的执行时间,并且两者内传入的字符串命名须统一才能生效,例如:
console.time('Scott');
console.log('seven');
console.timeEnd('Scott');
seven
Scott: 0.256ms
代码段中三处一致才是正确的用法。
正文
接下来我们来讨论我们常用的jQuery查找dom方式:
1.$(‘.parent .child'); 2.$(‘.parent').find(‘.child'); 3.$(‘.child','.parent');
其中方式1和方式3都是基于jQuery的selector和context的查找方式,既我们最常用的jQuery()或者$() ,
详细即为:
jQuery = function( selector, context ) {
// The jQuery object is actually just the init constructor 'enhanced'
// Need init if jQuery is called (just allow error to be thrown if not included)
return new jQuery.fn.init( selector, context );
}
基于jQuery(1.11.3)70行处,为该方法的入口,他做的所有事情就是创建了一个jquery.fn上的init方法的对象,我们再来细看这个对象是什么:
init = jQuery.fn.init = function( selector, context ) {
var match, elem;
// HANDLE: $(""), $(null), $(undefined), $(false)
if ( !selector ) {
return this;
}
// Handle HTML strings
if ( typeof selector === "string" ) {
if ( selector.charAt(0) === "<" && selector.charAt( selector.length - 1 ) === ">" && selector.length >= 3 ) {
// Assume that strings that start and end with <> are HTML and skip the regex check
match = [ null, selector, null ];
} else {
match = rquickExpr.exec( selector );
}
// Match html or make sure no context is specified for #id
if ( match && (match[1] || !context) ) {
// HANDLE: $(html) -> $(array)
if ( match[1] ) {
context = context instanceof jQuery ? context[0] : context;
// scripts is true for back-compat
// Intentionally let the error be thrown if parseHTML is not present
jQuery.merge( this, jQuery.parseHTML(
match[1],
context && context.nodeType ? context.ownerDocument || context : document,
true
) );
// HANDLE: $(html, props)
if ( rsingleTag.test( match[1] ) && jQuery.isPlainObject( context ) ) {
for ( match in context ) {
// Properties of context are called as methods if possible
if ( jQuery.isFunction( this[ match ] ) ) {
this[ match ]( context[ match ] );
// ...and otherwise set as attributes
} else {
this.attr( match, context[ match ] );
}
}
}
return this;
// HANDLE: $(#id)
} else {
elem = document.getElementById( match[2] );
// Check parentNode to catch when Blackberry 4.6 returns
// nodes that are no longer in the document #6963
if ( elem && elem.parentNode ) {
// Handle the case where IE and Opera return items
// by name instead of ID
if ( elem.id !== match[2] ) {
return rootjQuery.find( selector );
}
// Otherwise, we inject the element directly into the jQuery object
this.length = 1;
this[0] = elem;
}
this.context = document;
this.selector = selector;
return this;
}
// HANDLE: $(expr, $(...))
} else if ( !context || context.jquery ) {
return ( context || rootjQuery ).find( selector );
// HANDLE: $(expr, context)
// (which is just equivalent to: $(context).find(expr)
} else {
return this.constructor( context ).find( selector );
}
// HANDLE: $(DOMElement)
} else if ( selector.nodeType ) {
this.context = this[0] = selector;
this.length = 1;
return this;
// HANDLE: $(function)
// Shortcut for document ready
} else if ( jQuery.isFunction( selector ) ) {
return typeof rootjQuery.ready !== "undefined" ?
rootjQuery.ready( selector ) :
// Execute immediately if ready is not present
selector( jQuery );
}
if ( selector.selector !== undefined ) {
this.selector = selector.selector;
this.context = selector.context;
}
return jQuery.makeArray( selector, this );
}
基于jQuery(1.11.3) 2776行处,该方法比较长,我就来大概说一下我对这个方法的了解:这里主要就是做了先对selector的判断,在判断完后,查找context如果存在就继续做对有context存在情况的处理,没有则进行没有context情况的处理,而方式1和方式3:
1.$(‘.parent .child'); 3.$(‘.child','.parent');
他们都要进入相同的判断步骤,即上面简要说明的判断流程,等到1和3判断完后所花费的时间基本差不多,但是1内部的选择器还需要花费时间去进行sizzle相关查找,得出:
$(‘.parent .child'); 走完流程花费的时间:a;$(‘.child','.parent'); 走完流程花费的时间:a; 几乎已经找到dom节点$(‘.parent .child'); sizzle相关查找选择器.parent .child花费的时间:b;$(‘.child','.parent');花费的时间:a;$(‘.parent .child');花费的时间:a + b;接下来我们来看实际的运行结果:
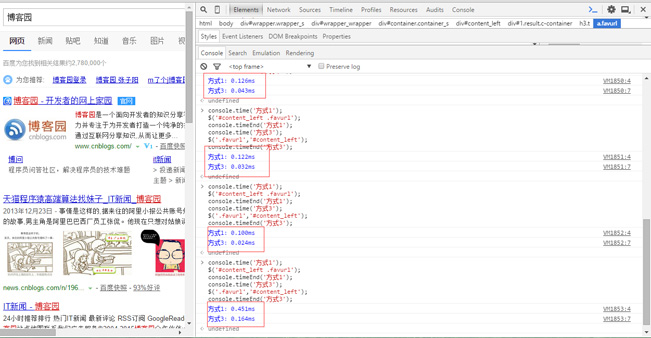
以百度页面为例,我们随便找出一组满足的范围来查找,博主进行多次测试,方式3的查找效率均快于方式1,且方式3的查找速度基本为方式1的3倍左右,即:

接下来我们我们加入jQuery的find方法进行比较,即为:
$(‘.parent .child');$(‘.parent').find(‘.child');$(‘.child','.parent'); 由于我们已有了之前的判断,基于他们三者都要进行jQuery()的查找,所以三者都在此花费a的查找时间,此时方式3已经基本找到了:
$(‘.child','.parent'); 花费时间:a;接下来方式1进行 ‘ .parent .child '选择器的查找,方式2进行jQuery的find方法查找,在此列出find的具体内容:
find: function( selector ) {
var i,
ret = [],
self = this,
len = self.length;
if ( typeof selector !== "string" ) {
return this.pushStack( jQuery( selector ).filter(function() {
for ( i = 0; i < len; i++ ) {
if ( jQuery.contains( self[ i ], this ) ) {
return true;
}
}
}) );
}
for ( i = 0; i < len; i++ ) {
jQuery.find( selector, self[ i ], ret );
}
// Needed because $( selector, context ) becomes $( context ).find( selector )
ret = this.pushStack( len > 1 ? jQuery.unique( ret ) : ret );
ret.selector = this.selector ? this.selector + " " + selector : selector;
return ret;
}
基于jQuery(1.11.3) 2716行处,在此我们可以看出find的过程比较简单,相较于方式1查找复杂的选择器(在查找选择器的过程中需要排除很多的情况,更多的时间花费在处理字符串上,即处理出我们想要表达的选择器)更高效一点,我们得出方式2优于方式1,下面我们拿三者来进行比较:
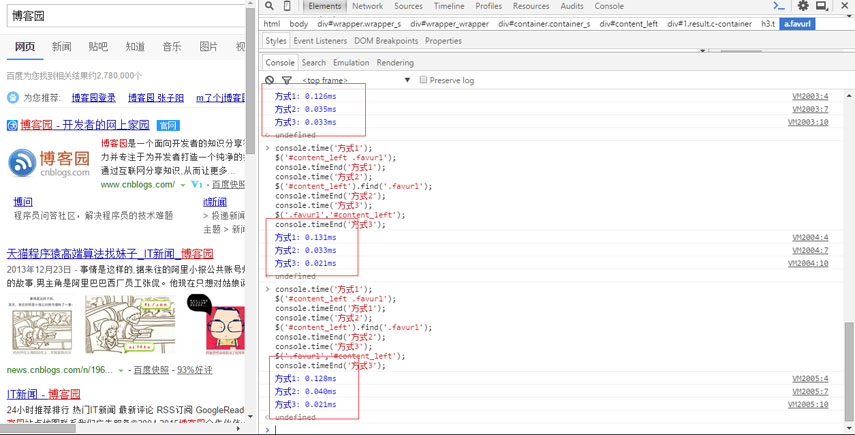
我们可以看出,方式1最慢,方式2和方式3不相上下,方式3略胜一筹,基本吻合我们的初衷,即为:
在基于jQuery查找dom的过程中能使用jquery的查找方式就使用,尽量不写复杂的选择器来表达我们想要查找的dom,效率极低。相反使用jquery的查找方式我们就能尽量排除复杂选择器的情况,极大提高查找效率。
由于方式2的使用可能会受限,所以在此我推荐大家使用方式3,即为:
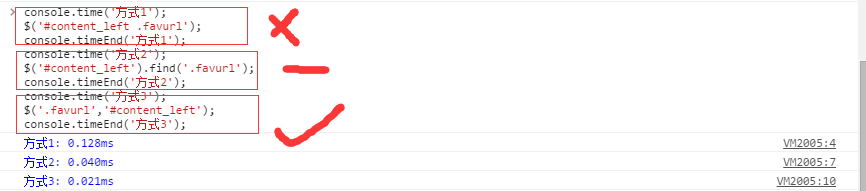
本文章地址http://www.vzeo.com/news/xuetang/800726.html 由 友站网 编辑整理,转载请注明出处

